This page presents a clear overview of the high-level architecture and core components that power Call-Emma.ai, offering insights into how the system is designed to deliver intelligent and scalable customer engagement.
High Level System Architecture
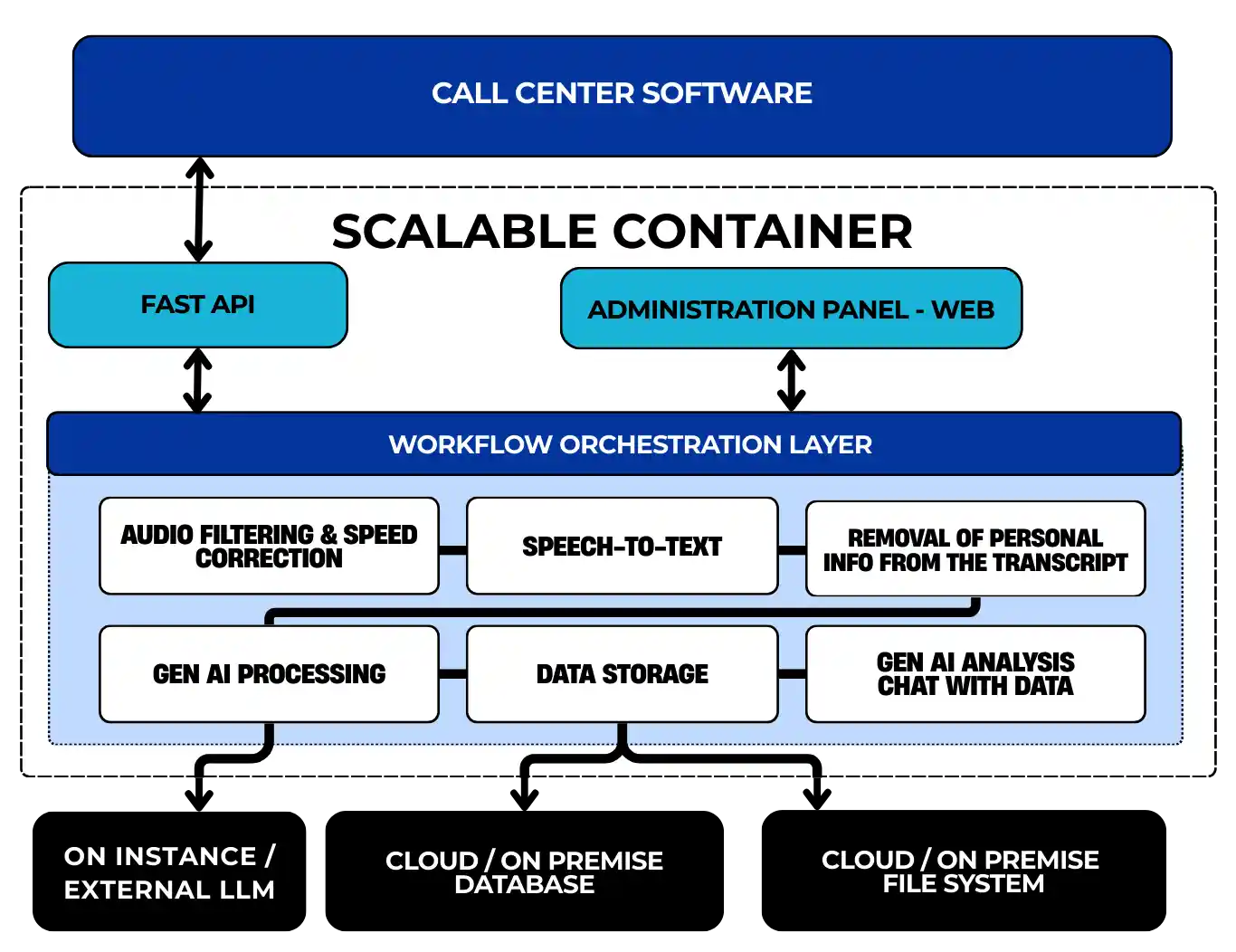
The image shown above is the system architecture for Call-Emma.ai
API Layer Component
FastAPI makes Call-Emma.ai faster and more responsive by handling requests with high performance. It ensures reliable and secure data handling, so your interactions are always accurate and protected. With built-in live documentation, updates and improvements roll out quickly—keeping your experience smooth and up to date.
Audio Uploads Components
Call-Emma.ai accepts audio recordings in WAV, MP3, and M4A formats—widely used in call center systems. These large files (2–50MB) are uploaded securely via FastAPI's optimized streaming upload mechanism, ensuring fast, reliable handling without timeouts or memory issues. This guarantees compatibility with common formats while supporting high-volume, real-world call recordings.
Queue Management Components
Call-Emma.ai is built to process high volumes of recorded conversations by applying prioritization and intelligent queuing to incoming job requests. Administrators can configure custom priority tiers to enable expedited processing—ideal for premium service levels or tiered pricing models. Additionally, robust logging and error handling ensure that failed jobs are automatically detected, logged, and reprocessed with minimal manual intervention.
Administration Panel Components
Customized Billing
Call-Emma.ai offers flexible billing capabilities, allowing each customer to be charged different rates based on usage volume and the specific features applied to their conversations. Each customer can be assigned a unique billing profile, ensuring accurate and customized rate application.
Usage Tracking
The administration panel also provides detailed usage visibility, with the ability to drill down by user, department, and client. This data can also be accessed programmatically via the API by the client or admin for seamless integration with external reporting or billing systems.
Tenant Management
The tenant management system enables administrators to activate, suspend, or remove clients, as well as manage and issue API tokens for secure system access.
Conversation Transcript Workflow Components
Audio Filtering & Speed Correction
To enhance the accuracy of voice-to-text transcription, Call-Emma.ai can apply preprocessing techniques to the audio. These include selecting the audio filtering model that removes background chatter and ambient noise, as well as a model that normalizes speed to correct irregular speaking rates. Together, these enhancements significantly improve voice-to-text transcription precision.
Speech-to-Text Translation
Speech-to-text transcription accuracy is a critical performance metric for any system. Call-Emma.ai supports multiple AI transcription models, including options for diarization, which can be selected and deployed as needed. When combined with advanced audio filtering and speed normalization, these models deliver significantly higher accuracy than transcription models alone.
Privacy and Personal Information
After the conversation transcript is generated, clients have the option to remove personal and protected information using a PPI (Personally Identifiable Information) removal model. With access to a range of widely adopted models, Call-Emma.ai ensures sensitive data is excluded from transcripts and helps clients meet national and regional compliance standards.
Generative AI Workflow
Preconfigured AI Prompts
Call-Emma.ai includes 27 expertly crafted AI prompts that generate actionable insights across seven strategic categories. These prebuilt and rigorously tested prompts support in-depth analysis of call content, categorization and tagging, quality assurance, agent performance, compliance adherence, and coaching effectiveness.
Customized AI Prompts
Call-Emma.ai enables the creation and execution of fully customized AI prompts, allowing clients to tailor analyses to their specific business needs. This flexibility supports the application of any number of AI-driven insights across each conversation.
Data Storage
Each stage of the processing pipeline can be securely stored, including the original and cleaned audio files, transcripts before and after privacy redaction, and the results of generative AI prompts. Data can be stored either on local instances or in cloud-based file storage systems, and the results of the generative AI analysis are fully compatible with a wide range of database platforms for seamless integration and downstream processing.
Generative AI Chat and Analysis
Users can interact with the system via API or AI-powered chat to query and analyze generative AI data. This functionality enables the creation of statistics across conversations, generation of visualizations, identification of outliers, and application of custom filters. The "Chat with Data" section on the Manage page highlights four key use cases.
LLM Options
On-Instance LLM Deployment
Administrators can deploy an LLM Ollama on their own infrastructure using containerization in Call-Emma.ai. This enables secure, on-premises processing of large language model (LLM) prompts. Ollama can be configured for optimal performance across CPU- or GPU-based servers, as well as cloud instances. While this approach offers enhanced control and data privacy, token generation may be slower compared to using an external API.
External LLM via API
Administrators can also integrate with external LLM providers through APIs, specifically using the OpenAI protocol. This approach offers quick deployment, minimal infrastructure overhead, and typically faster token generation due to the high-performance infrastructure maintained by the provider. When used in conjunction with Groq.com, the operating costs are significantly lower than running LLM inference on cloud instances. Please note that this approach may involve trade-offs in terms of data privacy, control, and customization compared to on-instance deployments.
Data Storage Compatibility
Data storage for files and database entries is highly customizable and designed to be compatible with existing systems, including cloud storage and databases, ensuring seamless integration and efficient performance across your infrastructure. All files generated or processed by the system can be saved, including uploaded audio, filtered and cleaned audio, transcripts, privacy-enabled transcripts, and all AI-generated outputs.